

Which Category is Best for YouTube: An Insider's Guide to Leveraging Data Insights (2023)

Abstract
Bottom Line Up Front: While the Audience prefers ‘Gaming’, ‘Entertainment’, and ‘Music’; YouTube appears to reward only these categories: “How to”, “Science & Tech”, and “Education”.
A media company wants to explore the best category to upload videos to YouTube. The study takes a YouTube trending videos dataset for the United States and explores it. The dataset was extracted, cleaned, and statistically tested. The analysis compares the video engagement metrics of ‘likes’, ‘dislikes’, ‘views’, and ‘comment_count’. These different groups were tested for normality via Shapiro-Wilk test. The results of the Shapiro-Wilk test confirmed that the stated variables are non-parametric. Furthermore, a Kruskal-Wallis test was appropriate to investigate differences between two or more groups. Resulting, in two or more groups being different. During data exploration a metric Engagement Per View EPV, was created with all four non-parametric variables. The result was a parametric variable, that tested positive for being perfectly Gaussian in the Shapiro-Wilk test. The exploration yielded interesting insights; When plotted individually, the categories that received the most engagement where: ‘Gaming’, ‘Entertainment’, and ‘Music’. However, when the ‘categoryid’ variable was plotted against EPV, the result was a bell-shape curve only over ‘How to’, ‘Science & Tech’, and ‘Education’.
Research Question:
Can a descriptive Kruskal-Wallis model be developed from the data?
Null Hypothesis H0:
There is no difference between the distributions of the scores of these four populations.
Alternative Hypothesis H1:
At least two of the four populations differ.
The contribution of this study to the field of Data Analytics and Video Marketing, is to create a Kruskal-Wallis test to investigate prime content categories on YouTube. With this information a media company can maximize the investment put into the video content. An article titled, Brand Engagement in Light of Post Content Type on the Facebook Platform in the Selected Industry, showcases a study using Kruskal-Wallis testing to explore engagement strength using the identical variables of ‘Likes’, ‘Views’, and ‘Comment Count’ (GATR, 2020). They found that these variables are key factors in overall content engagement and brand awareness. The Kruskal-Wallis H-test, tests the null hypothesis that the population median of all of the groups are equal. It is a non-parametric version of ANOVA (Scipy, 2020). Understanding these variables can help describe the relationship between the IV and DVs.
Data Collection
An opensource dataset of YouTube data containing the necessary variables about video uploads. A Kaggle dataset from www.kaggle.com. Kaggle is the opensource repository / organization that hosts the datasets. The dataset contains almost 202,201 rows (before any rows were removed) and 16 columns. The dataset is limited to only 3 years of YouTube’s trending videos; Uploaded from 2020 – 2023. The dataset has multiple columns for possible exploration. Different audiences watch shows of different content types all over the planet. Delimitations for this analysis, only 5 columns of the dataset will be used as they are factors of engagement: The ‘category’, ‘views’, ‘likes’, ‘dislikes’, and ‘comment_count’; The dataset is easy to work with because the columns are whole integer values. The ‘categories’ is the independent variable to be explored.
Available to the public via Kaggle.com, meaning that the dataset may be limiting in accuracy and completeness. The clickable link is located below:
https://www.kaggle.com/datasets/datasnaek/youtube-new?select=USvideos.csv
Below is a picture of the variables to be used along with the data type.

Data Gathering:
Planning and direction of data gathering was from opensource repositories (Google). Searching for keywords such as “YouTube”, “Videos”, “upload times”, “+ .csv”. Next, selecting the 1st to 3rd ranked pieces of content and checking the availability (a reachable csv file). Each csv file was inspected for quality such as “length” (at least 7k rows), data cleanliness, massive gaps in data. Cross examined to ensure there was enough relevant variables to create an ‘X’ and ‘Y’ axis. Available to the public via Kaggle.com means that it may be limiting in accuracy and completeness. In Kruskal-Wallis, the dependent variable must be a continuous (interval or ratio) level of measurement (Statology, 2019). Fortunately, all dependent variables are continuous. The dataset is 2.1 % sparse and all missing or null columns will be dropped when cleaning the dataset.
Data Extraction and Preparation:
A KDE plot is used to visualize the distribution and Shapiro-Wilk is used to test for normality. Kruskal-Wallis is germane to studying this data because it can compare distributions of non-parametric data. However, the Kruskal-Wallis test does not assume normality in the data (Statology, 2019). Overall, this is an exploratory quantitative data analytic technique and a descriptive statistic. The tools used will be Jupyter Notebook operating Python code, running statsmodel API as a reliable open-source statistical library. Due to the data size, a Pandas data frame will be called, same with Numpy and Seaborn will be used for visualizations. A Kruskal-Wallis test will be the statistical test used with statsmodel’s Kruskal function. A presentation layer of Univariate and Bivariate graphs along with all code.
Python will be used for this analysis because of Numpy and Pandas packages that can manipulate large datasets (IBM, 2021). The tools and techniques are common practice in the industry and have consensus of trust. The technique is justified through the integer variables necessary to plot against a timeline. In so doing, may just reveal different modes of frequency distribution. Another reason why Kruskal-Wallis test is ideal because the data is based off of human viewing behavior, which is notoriously skewed. Because of the size of the dataset, pandas and Numpy will be called. Python is being selected over SAS because Python has better visualizations (Panday, 2022).
Analysis
In order to find statistically significant differences, the proposed end state is a Kruskal – Wallis descriptive statistical model that can compare the distribution shapes of the targeted groups (Statology, 2019). A visualization of the frequency distribution of EPV against video categories. Available will be a cleaned dataset of all the correctly labeled columns and rows, for replication. A better understanding of previously stated groups with exploratory graphs, giving support as to what time engagement maybe highest. Lastly, a copy of the Jupyter NoteBook with the Python code will be available, along with a video presentation. According to the same study Kruskal-Wallis was instrumental in support for alternative hypothesis, against other categorical variables. (GATR, 2020). Below is the Python code along with visualizations.
Click the link here for: the code located on Github.



Univariate Exploration
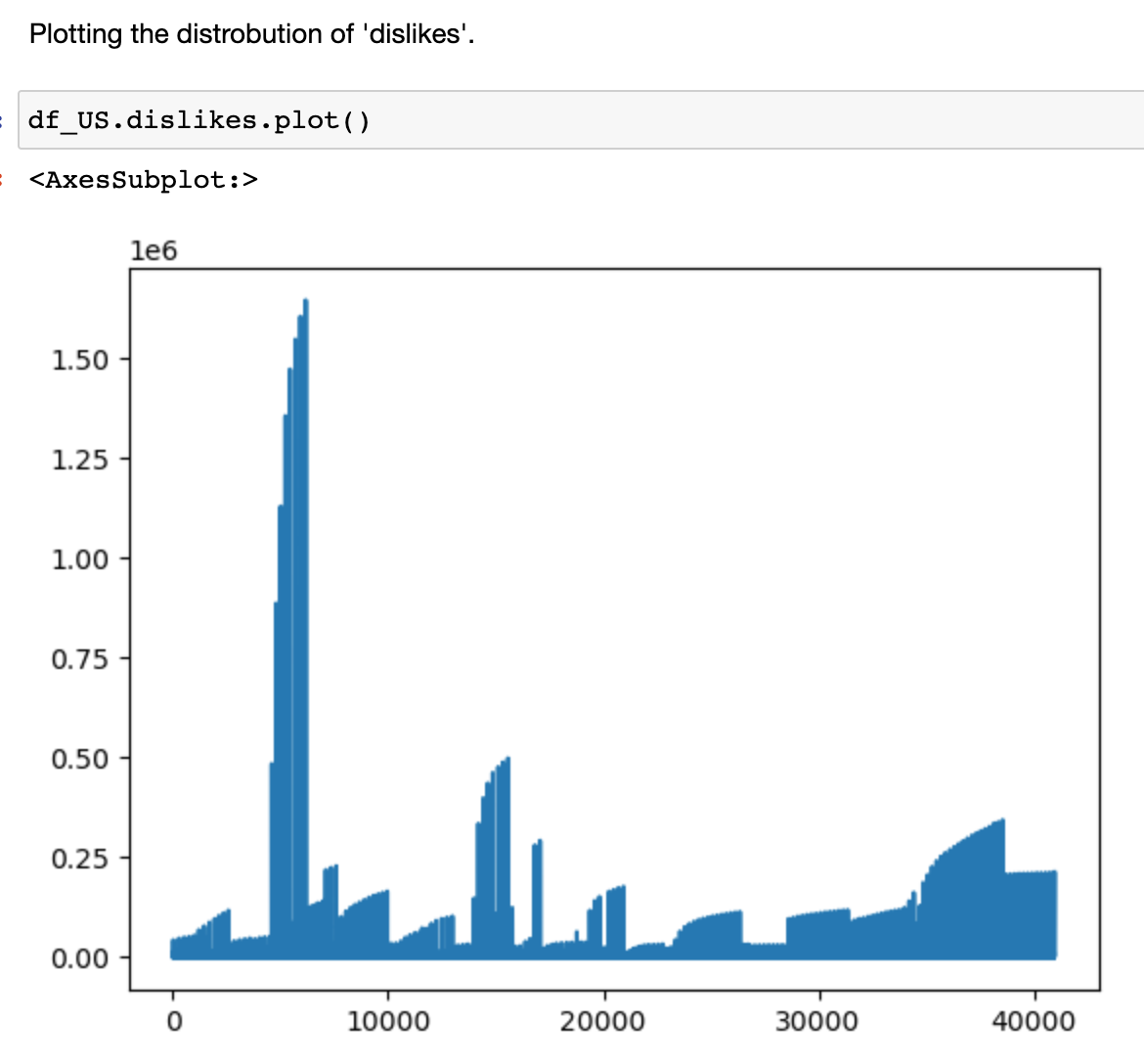
Notice that the frequency distribution appears multi-modal and right-skewed. The variables appear to be non-parametric. The same pattern will be apparent in the following visualizations of ‘comment_count’, ‘views’, and ‘likes’. The multi-modality will be more pronounced. Noticeably, the fourth visualization ‘dislikes’, will take a sharp distribution direction change and be commandingly left-skewed.



Bivariate Exploration
Category ID List
1 = Film& Animation,
2 = Autos & Vehicals
10 = Music
15 = Pets & Animals
17 = Sports
18 = Short Movies
19 = Travel & Events
20 = Gaming
21 = Vlogging
22 = People & Blogs
23 = Comedy
24 = Entertainment
25 = News & Politics
26 = How to
27 = Education
28 = Science & Tech
29 = Non-Profits & Activism
30 = Movies

Notice the frequency spike over category 10 “Music” , when ‘views’ are plotted against video category. It appears the audience enjoys “Music” the most.


Based on raw frequency count, the above bar graph highlights that “Gaming”, “Entertainment”, then “Music” are what audience prefers.
However, when the follow feature is engineered, it can be used as a tool for discovery.

Creating the KPI for exploration.¶
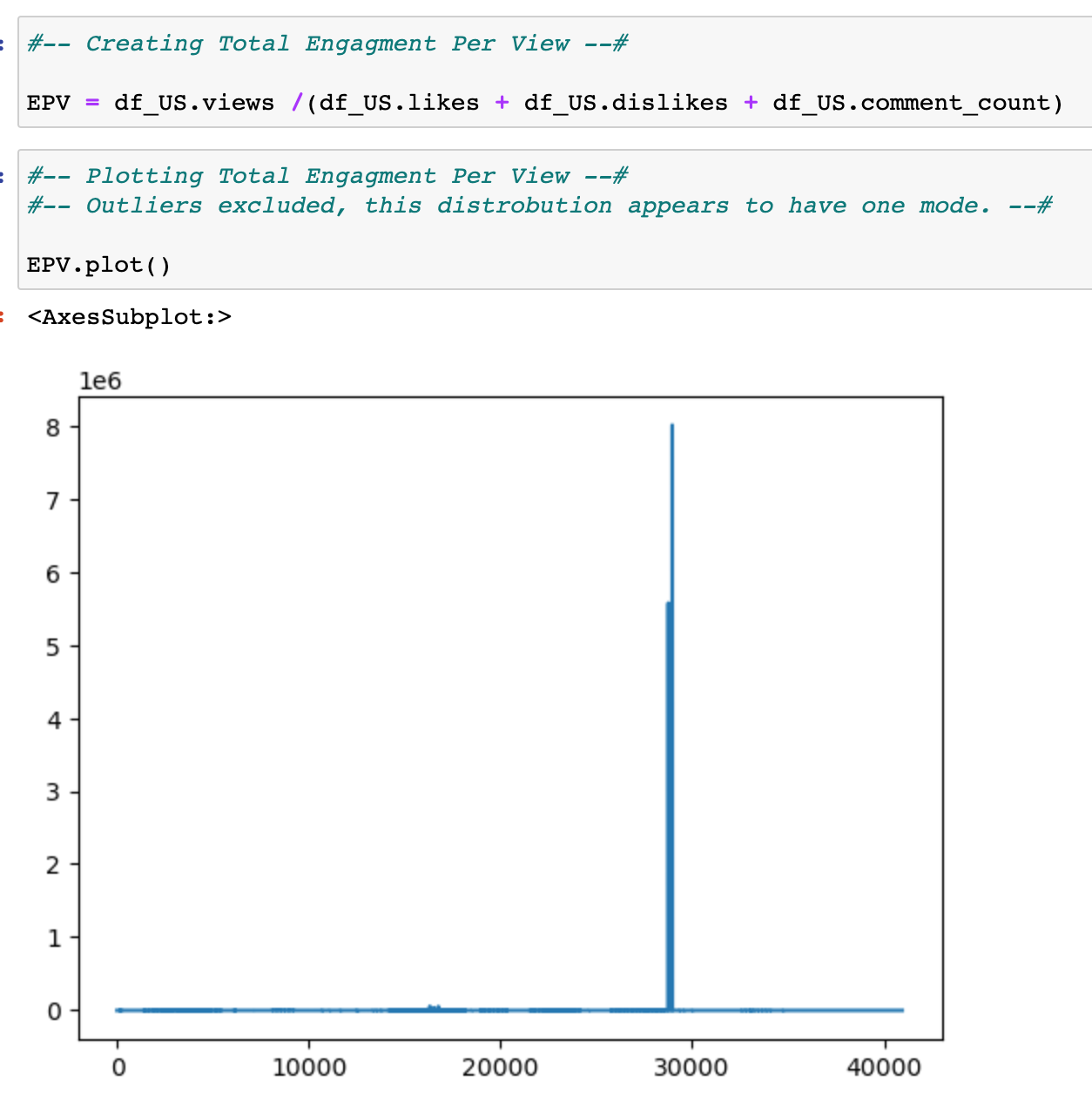
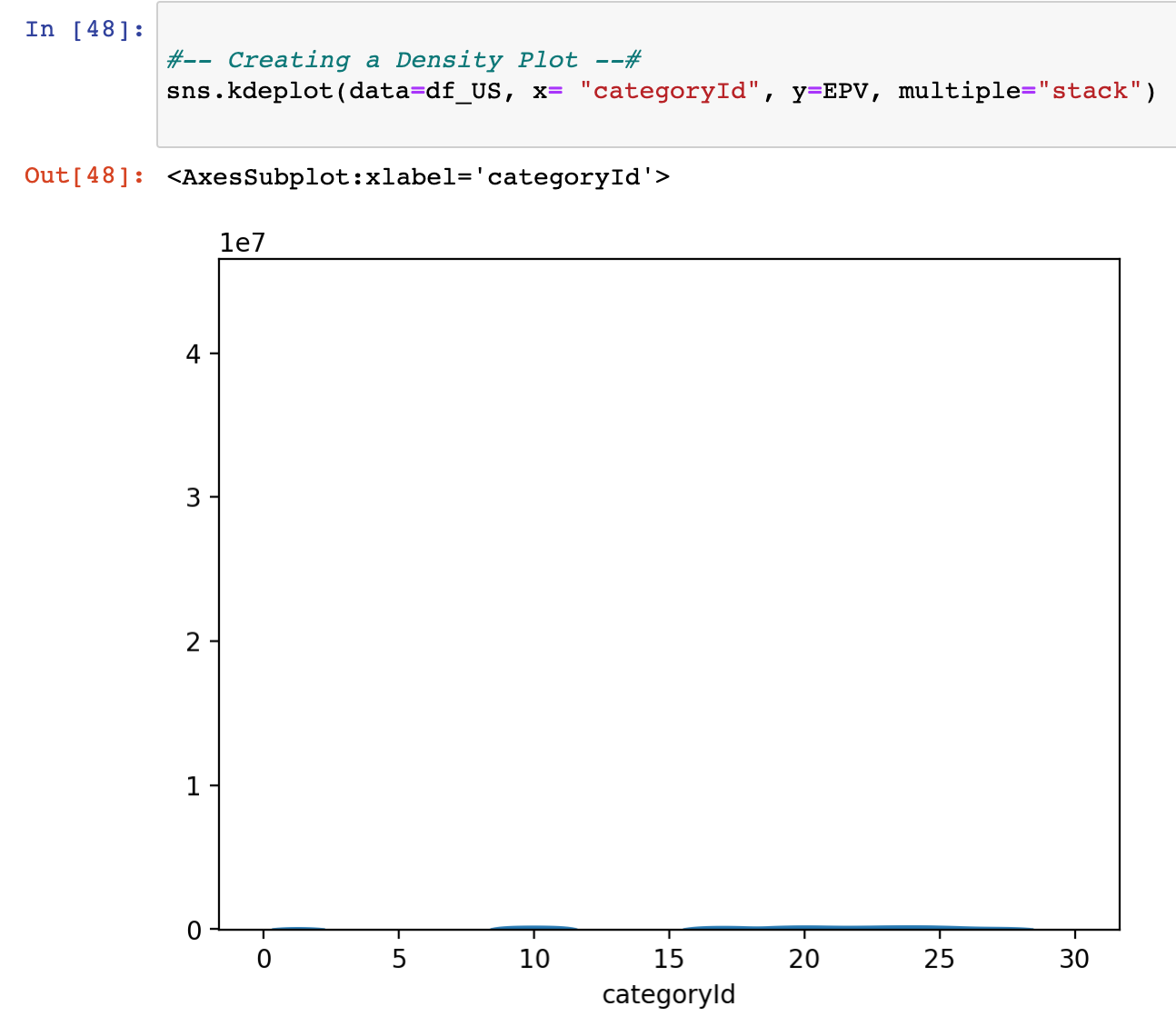
When EPV is plotted against ‘categoryid’ in a density plot, there is a very slight evidence of positive engagement over categories: 10, 16 - 28; However, not too descriptive based on raw frequency density.
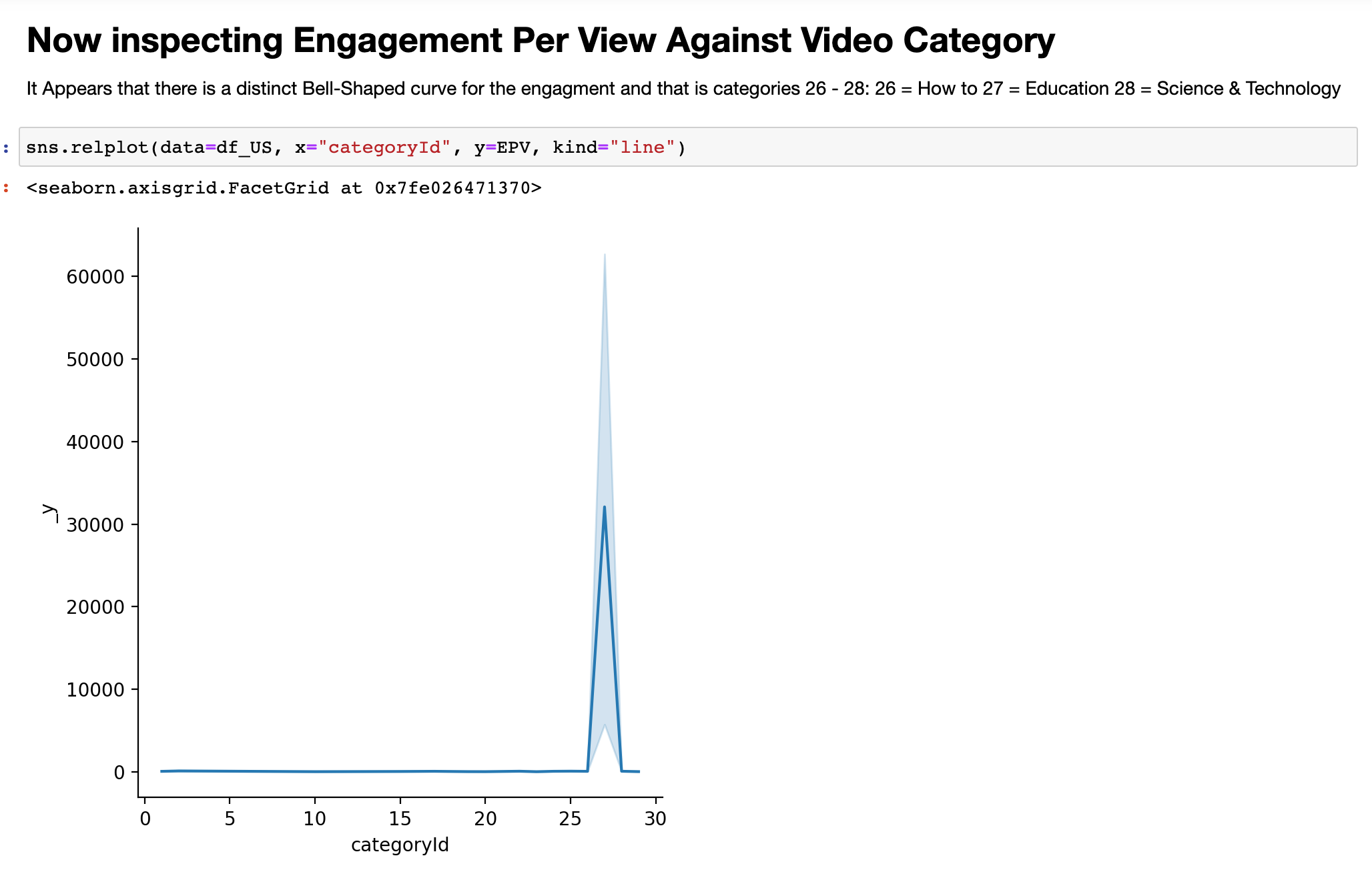
The above graph shows that when EPV is plotted directly against ‘categoryid’, there is a distinct bell-shaped curve of postitive Engagement Per View directly over 26 -‘How to’, 27 - ‘Education’, and 28 - ‘Science & Tech’.
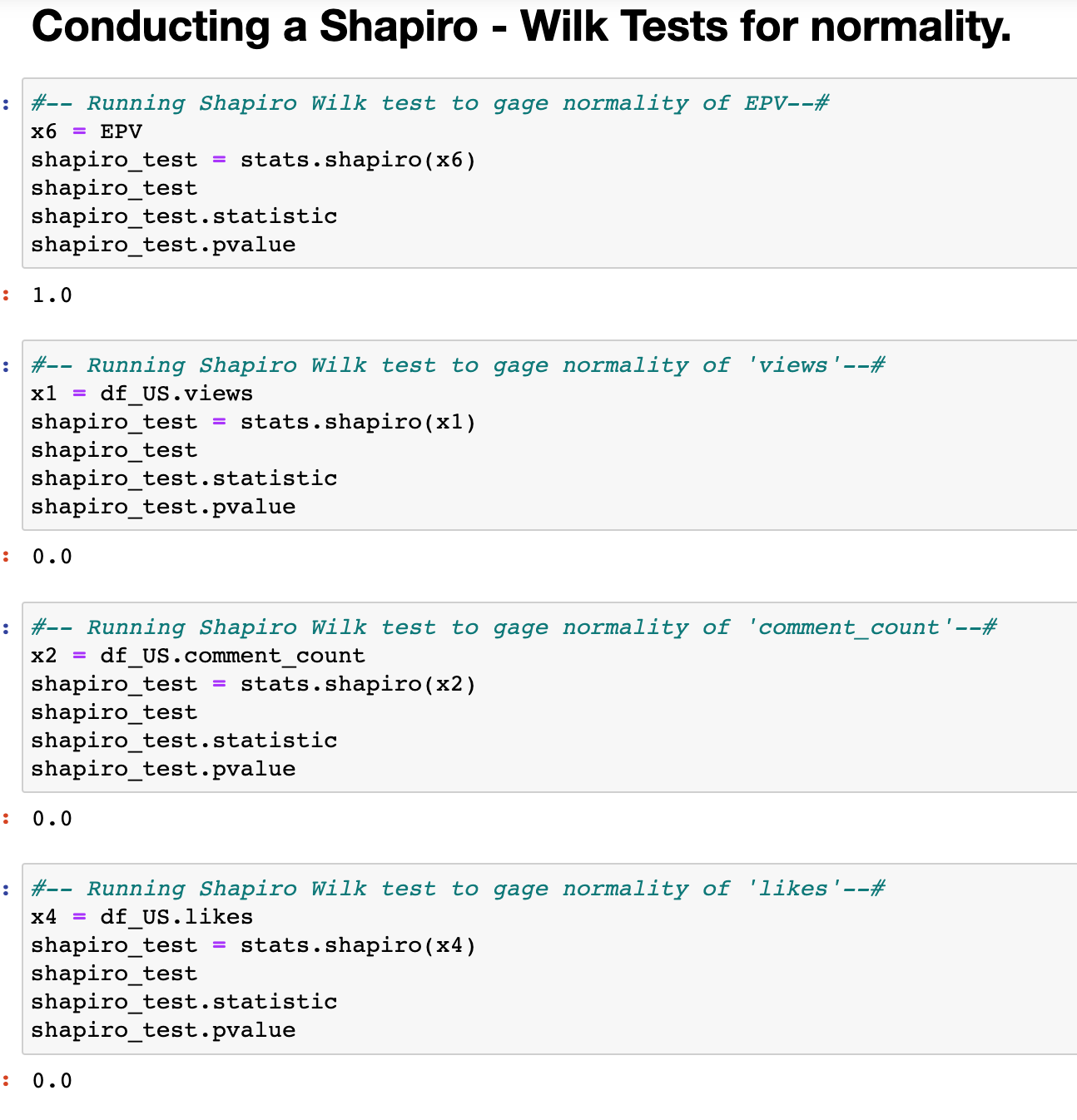
Conducting a Shapiro - Wilk Tests for normality.¶
The below Shapiro -Wilk test of EPV outputs a p-value =1; Which is greater than .05, indicating that EPV is a ‘normal’ distribution. On the other hand, the remaining variables all had p-values = 0.0, less than .05, and therefore the null hypothesis of ‘normality’ is rejected.
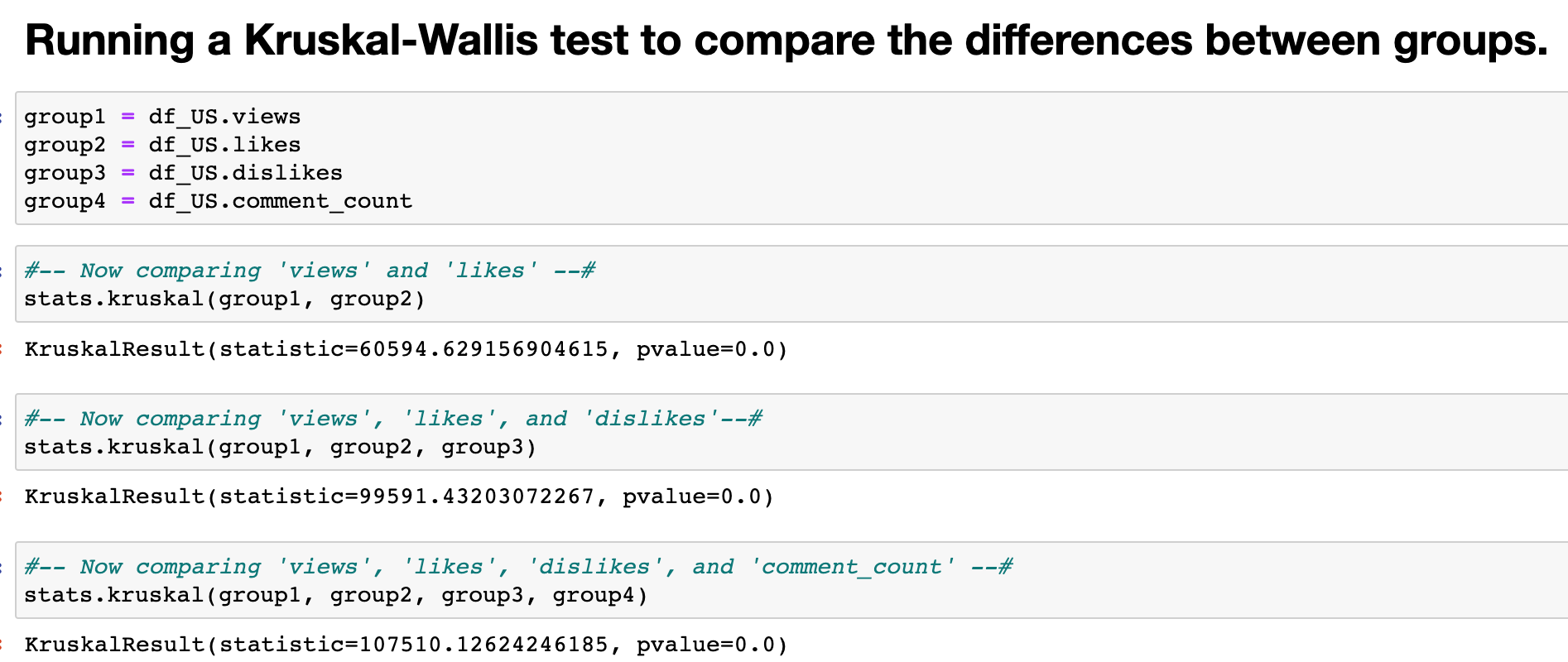
Because of the non-parametric nature of the variables, the Kruskal-Wallis test for similarity between groups is appropriate. The resulting output for all Kruskal-Wallis tests between group combinations yielded the same p-values equaling zero. Secondly, the H-statistic continued to increase as more groups were added. Ergo, rejecting the null hypothesis in support of the Alternative Hypothesis; At least two of the four populations differ.
Data Summary and Implications
The Kruskal–Wallis test answers the research question with the stated groups and the Null Hypothesis was rejected in support of the Alternative Hypothesis; Therefore, none of the Individual Variables came from a normal distribution. Interestingly, when the variables where combined into the metric EPV, EPV tested positive to being perfectly Gaussian, via the Shapiro-Wilk test. Moreover, except for ‘dislikes’, the remaining variables indicate similar multi-modal distributions. When studied individually or against ‘categoryid’, the variables exhibit the same non-parametric behavior but skewed in the opposite direction. The bell-shaped distribution created with EPV only covers the video categories of: “How to”, “Science & Tech”, and “Education”. What this research might imply is that said named categories are the only ones that receive positive Engagement Per View. Since the dataset only contained trending YouTube Videos in the United States, one recommended course of action is to compare the datasets of other countries that are available to the public at Kaggle.com. One limitation of the analysis is that it is a snapshot in time. Therefore, one direction for future study with the dataset, is to explore the video ‘categories’ variable with the same or additional engagement variables. The mission statement of YouTube is, “To give everyone a voice” (about.youtube). However, if your “voice” is categorized under the three-stated-categories, it has a higher probability of engagement. Another direction for future study, would be to compare video ‘titles’ variable against the same engagement metrics and continue quarterly mining for trending key-word phrases.
Work Cited
GATR Journal of Management and Marketing Review - researchgate.net. (n.d.). Retrieved February 9, 2023, from https://www.researchgate.net/profile/Richard-Fedorko/publication/347381995_Brand_Engagement_in_the_Light_of_Post_Content_Type_on_the_Facebook_Platform_in_the_Selected_Industry/links/6110e7a00c2bfa282a2f9401/Brand-Engagement-in-the-Light-of-Post-Content-Type-on-the-Facebook-Platform-in-the-Selected-Industry.pdf
J, M. (2019, June 3). Trending YouTube video statistics. Kaggle. Retrieved February 8, 2023, from https://www.kaggle.com/datasets/datasnaek/youtube-new?select=USvideos.csv
Pandey, Y. (n.d.). SAS vs python. LinkedIn. Retrieved February 8, 2023, from https://www.linkedin.com/pulse/sas-vs-python-yuvaraj-pandey/
Python vs. R: What's the difference? IBM. (n.d.). Retrieved February 8, 2023, from https://www.ibm.com/cloud/blog/python-vs-r
Scipy.stats.kruskal#. scipy.stats.kruskal - SciPy v1.10.0 Manual. (n.d.). Retrieved February 8, 2023, from https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kruskal.html
Zach. (2022, March 7). Kruskal-Wallis test: Definition, formula, and example. Statology. Retrieved February 8, 2023, from https://www.statology.org/kruskal-wallis-test/
Check out other blogs on the similar topics:
When should you upload to YouTube in 2023?
Podcast Interview with ChatGTP
Forecasting with Time Series Data
Natural Language Processing on IMDB movie comments
Principal Component Analysis with Telecom Data
Market Basket Analysis for Prescription Data
Hacking the System: Optimizing Humans to Increase Page Ranking
Drug Overdose Deaths Data Mining Exploration
Hospital Readmission Tool Dashboard
Data Analytics and Police Funding